It’s been almost 2 weeks since Meta dropped a bombshell on the AI world by openly releasing their updated LLAMA model. As the hype dust settles, let’s have a look at how it can be used in commercial and academic environment and manage our expectations accordingly.
Quick Background
LLAMA 3 was released back in April 2024 and while it was pretty good and pretty much blew all other open models out of the water, it was comparable to GPT-3.5. With 70 billion parameters and the size of around 40GB, it could be ran fairly easily on consumer grade equipment.
Yet still, with GPT-4 followed by GPT-4o, all focus was back on OpenAI.
Fast forward to July, and Meta releases version 3.1. This time, however, they include the crown jewels: a 405-billion parameter variant. In addition to MMLU dominance in the open model space, they claim it can match the performance of GPT-4o and Claude Sonnet 3.5.
It sounds a bit too good to be true. What was the catch? And why would Zuckerberg give it up for free?
Test Environment
In am in a somewhat unique position to be able to test LLAMA in both academic and commercial applications. But first, we need to run that thing. At a whopping 231 gigabytes, the 405b variant won’t fit any consumer GPU VRAM. It would require ten RTX 4090s running on a single motherboard. While GPU clusters can be built, they do not fall under the scope of commodity hardware.
With that being said, I had to settle for a GPU/CPU shared operation. The tests were conducted on two separate builds, one using DDR4 memory and Intel CPUs from 2017, the other based on 2024 AMD DDR5. Both were equipped with 256 GB of RAM and a single RTX 4090 with 24 GB of VRAM. Detailed builds are listed in the Performance section.
One of the goals of my test was to compare the 70b and 405b variants and see if the latter’s size cost comes with a measurable performance benefit. (Yes, it most definitely does)
School
When llama 3.1 dropped, I was in the middle of developing an LLM-based primer for game theory simulations. In a nutshell, it needs to describe an environment with multiple players competing for their preferred outcomes, with various salience and influence factors.
The undisputed champion of LLMs at that point were GPT-4o and Claude 3.5, and I used it them as baseline reference for the following scenario. The reference value was calculated as a simple average:
VAL_REF = (VAL_GPT + VAL_CLAUDE) / 2
In our game, we analyze the importance of Green Energy sources (i.e. renewables) for EU member states. My LLM primer needs to quantify each country’s three starting positions:
- Importance – how big of an issue this presents for each state
- Power – how much influence each state has to push for their goal
- Goal – here, it’s the number of years after which at least 50% of energy production must be from renewables
The parameters are listed in the order of increasing abstraction. Importance can be inferred directly from publicly available news sources. Power has to be based on more general influence level of a given state narrowed down to this particular matter. Finally, to quantify a number of years requires the largest amount of LLM analytic power.
While both Importance and Power were explicitly capped at the max value of 10, Goal was an open ended question. It was later normalized to range 0-10, using the formula:
VAL_NORMALIZED = ROUND(VAL_REPLY * 10 / MAX(ALL_REPLIES))
I also removed 3 micro-nations from my experiments: Luxembourg, Malta and Cyprus. Due to their size, the amount of training data pertaining to those states was disproportionally smaller versus their full size counterparts.
The prompts used with GPT, Claude and LLAMA were very similar and their essence was virtually identical. The only differences had to do with formatting and using Assisstent vs Chat models.
Here’s the results. Let’s reverse the order and look at the most abstract parameter first:
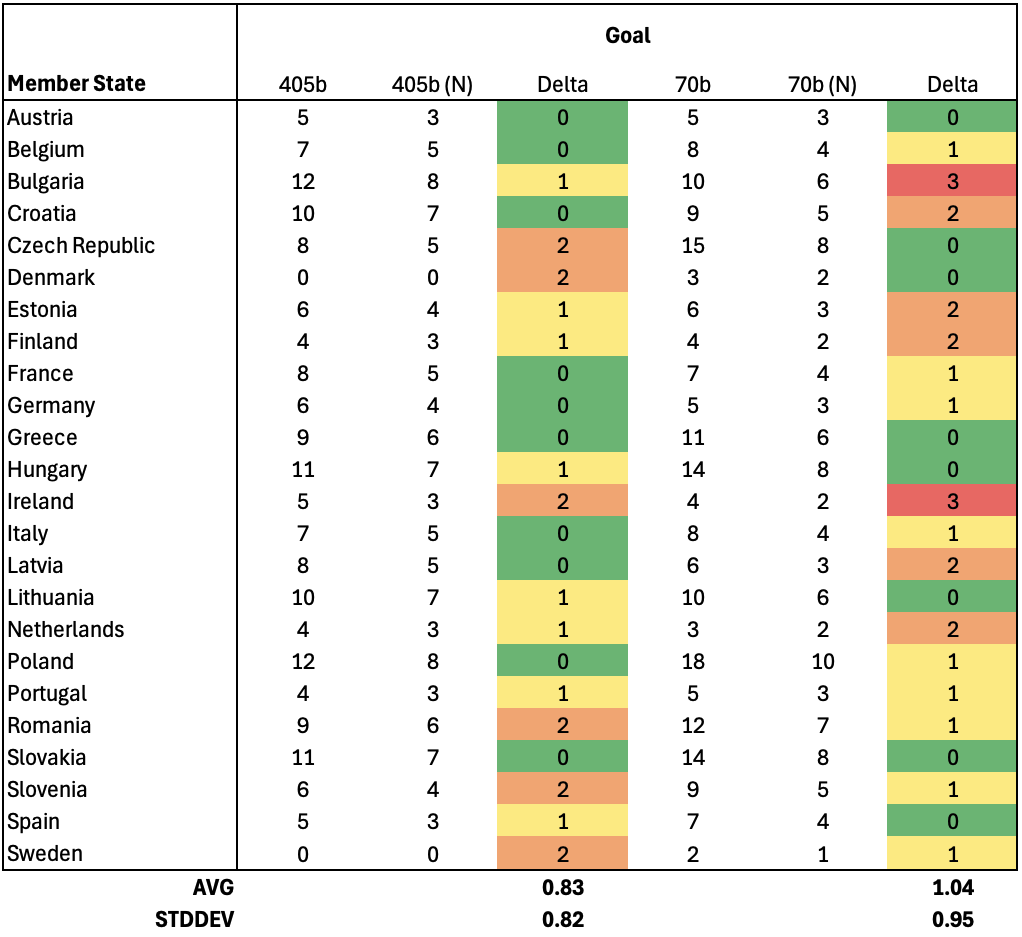
This is the parameter I normalized to range 0-10, hence those extra columns. As shown, the 405b variant gives estimates within 0.83 years (8.3%, σ ~ 0.82) of our reference online models. This is a very good result, considering that this is a highly speculative, open ended question. For what it’s worth, we assume that the mean of GPT & Claude gives us a true value, but it could very well be the other way round, and LLAMA might be closer to truth. Either way, we’ve got a self-hosted model giving us an abstract estimation within a few % of the industry titans. This is impressive. The smaller 70b variant isn’t that far off, with an average delta of 1.04 years (10.4%, σ ~ 0.95). But again, due to the nature of this prompt, it would be difficult to quantify a performance loss associated with fewer parameters.
Next, let’s have a look at our players influence:
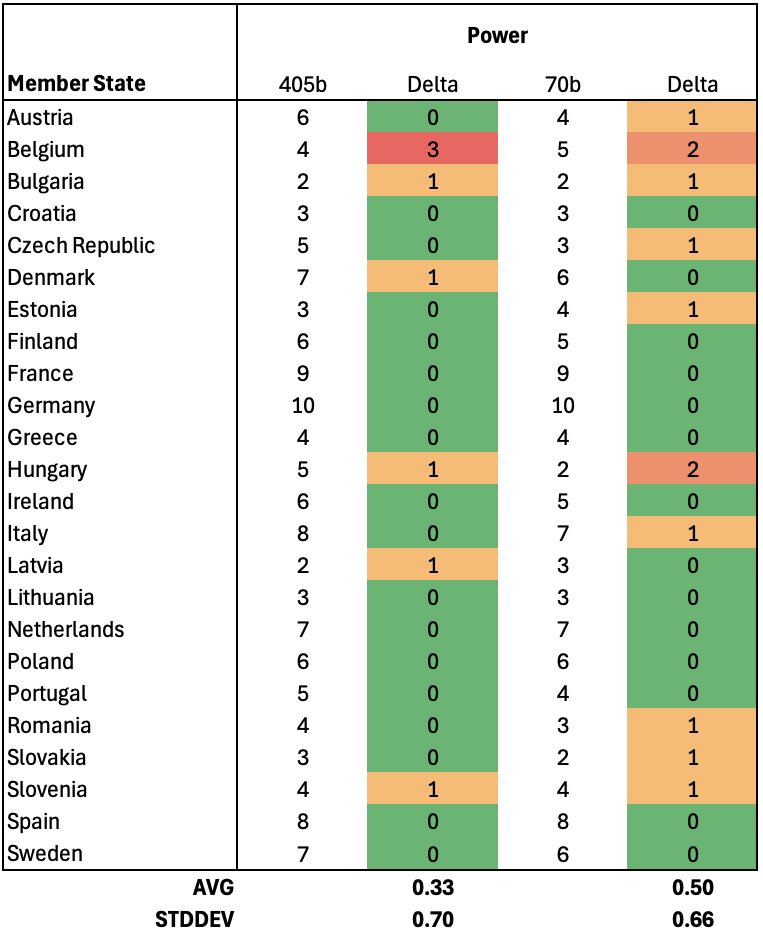
Things are getting real. Our average difference between LLAMA 405b and GPT/Claude is now down to 0.33 (3.3%, σ ~ 0.7). For all intents and purposes we are now matching the estimates of online models. Our self-hosted AI is performing equally well for academic research and we’re paying a total of $0 for the privilege (more on that later). One might point out that the 70b variant isn’t that far behind, with the average delta of half a year (5%, σ ~ 0.66). Let’s have a look at the final table.
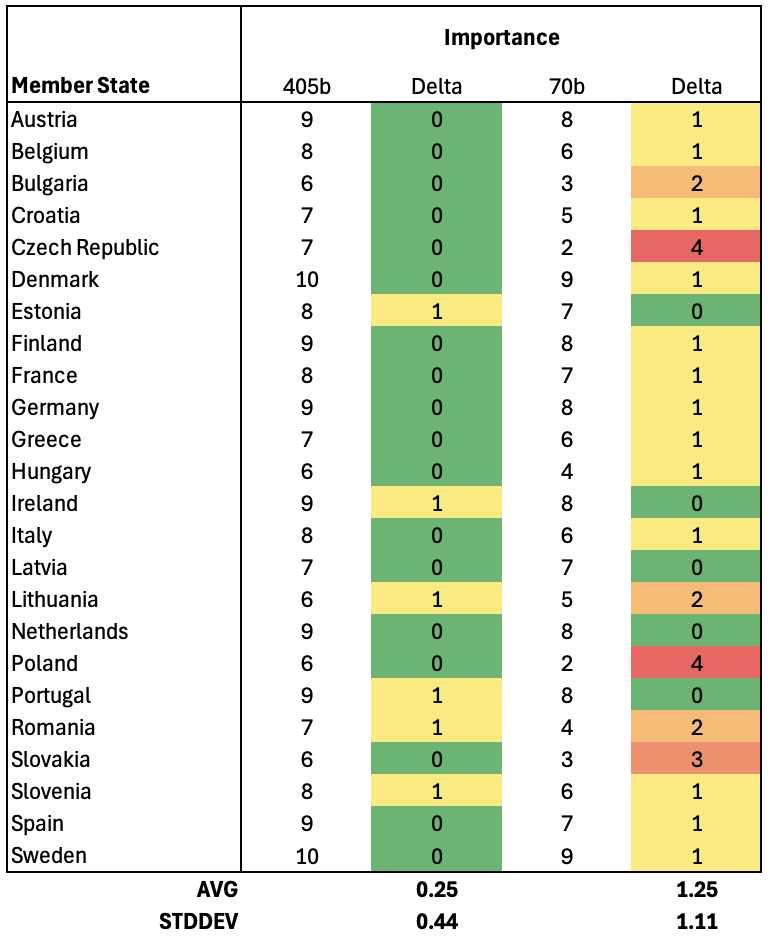
The 405b variant manages to improve even further. Our average difference is now a quarter of a point (2.5%, σ ~ 0.44). All the major EU players – based on their population (and therefore amount of train data) – yield a perfect match. Microsoft execs who signed off on their $11B investment into GPT might be feeling somewhat uncomfortable. At least here, the gap between 405b and 70b variants becomes even more apparent, with the smaller model performing 5 times worse (12.5%, σ ~ 1.11).
This looks almost too good to be true. Let’s leave the academia and turn into the world of Corporate America.
Work
One of the AI projects I am working on involves parsing documents. Large, massive quantities of poorly-formatted, non-standardized, error-prone letters received in variety of formats. What’s great about this particular workflow, is that we do have a reference value which we expect to extract from each document, which in turn allows us to determine if the AI parse was successful or not. Think of an itemized bill for which we’ve got a total.
This project has been developed using GPT-4o, which yielded the following results per item:
| GPT-4o (Assistant API) | |
| Process time | μ ~ 6s, σ ~ 9.2s |
| Avg cost per document | $0.08 |
| Success rate | 92% |
You might notice a very large standard deviation of the processing time. That’s because GPT will randomly hang on some random queries (~5%) for 45+ seconds before returning the answer. Strangely, a regular web-based subscription does not suffer from this delay. It only affects their business assistant API.
To switch from OpenAI’s API and provide a more universal implementation moving forward (in case more open models drop in the next few months), I migrated the workflow to OpenWebUI. It conveniently provides document parsing and Ollama interfacing in one neat API package. Results on the same sample batch are shown below:
| LLAMA 3.1:405b | LLAMA 3.1:70b | |
| Process time | μ ~ 31s, σ ~ 1.4s | μ ~ 14s, σ ~ 1.3s |
| Avg cost per document | $0 | $0 |
| Success rate | 97% | 92% |
So here’s where things get interesting. My OpenWebUI+LLAMA combo actually outperforms GPT-4o in terms of success rate. The processing times were obviously much longer, but also much more stable. How is that even possible? A close analysis of those individual failed items reveals the following pattern:
- LLAMA usually fails on items that require more complex calculations (adding various numbers together, excluding some transactions, etc.)
- GPT usually fails on items with more advanced formatting or with multiple mentions of the same amount (more typical AI hallucination)
My suspicion is that the difference isn’t necessarily caused by LLM performance, but instead by the document (PDF/Word) parser. As it’s usual in computer science: garbage in yields garbage out. With OpenWebUI, this is handled by a two-layer RAG pipeline, comprising BM25 + CrossEncoder re-ranking. It allows for fine parameter tuning, although it was not required in my case and I ran with the default setup.
OpenAI’s process is internal, meaning we cannot control the parsing directly.
Either way, to say the results were impressive would be a massive understatement. Here we have an open, self hosted model, actually doing a better job at a very “corporate” task than its industrial counterpart.
Performance
There were 3 hardware configurations used for testing, all with 256 GB of RAM:
- CPU+DDR4: 2x 10-core Xeon 4114 with PCIe 3.0 and DDR4 memory
- GPU+DDR4: 2x 10-core Xeon 4114 with PCIe 3.0 and DDR4 memory + RTX 4090
- GPU+DDR5: 24-core Threadripper 7960X with PCIe 5.0 and DDR5 memory + RTX 4090
Memory frequencies:
- DDR4: 2400 MT/s
- DDR5: 5600 MT/s
All configurations were tested using both Linux and Windows operating systems, with the following Nvidia driver versions:
- Linux: 550.90.07
- Windows: 560.70 WHQL
In addition, Linux test were performed on two different kernel versions:
- 5.15
- 6.8
CPU+DDR4 and GPU+DDR5 showed no performance differences between Linux and Windows. GPU+DDR4 revealed a substantial difference, with Windows outperforming Linux by 25-30%. Neither category showed differences between 5.x and 6.x Linux kernels.
Because of those differences (or lack thereof), there are ultimately 4 different configurations I plotted. The results below show an average time to execute a prompt for the EU Green Energy game primer:
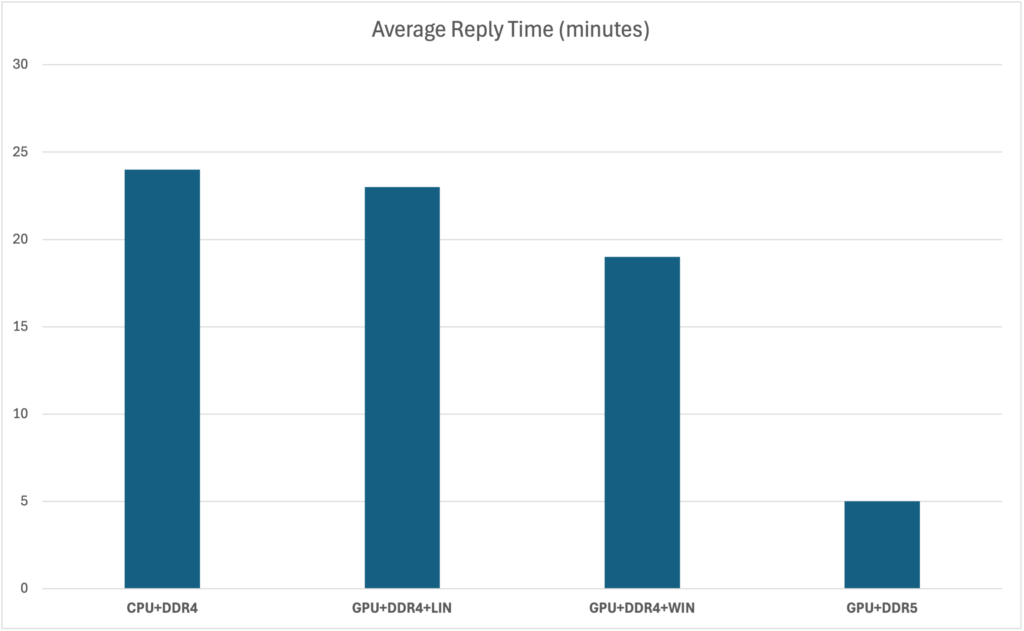
The results shouldn’t be that surprising, considering we’re using a 231 GB model, but have only 24 GB of VRAM available for our GPU. As a result, CPU does most of the heavy-lifting, with GPU kicking in for 10-15% of the initial calculation (ollama actually reports the model to occupy 10% GPU / 90% CPU). DDR5+Threadripper benefit from over double the memory speed and quadruple the PCI speed, making it a very cost efficient way to achieve a reasonable performance.
Yet still, this case shows the biggest difference between online vs on-premise model. GPT responded on average in 15-30 seconds, meaning our best config was 20x slower. To take on GPT, we’d have to fit our complete model in VRAM, at which point we’re looking at a cost of $75-100k per device. This suggests that the best workloads for LLAMA (unless you can spend that kind of money) are non-real time. For instance – the document parser I described does not care too much about execution time (within reason). It’s one of your typical batched workloads that run at night, when the cost per kWh is lower and ample resources are available.
There is another solution coming up really soon: Apple Silicon. Due to its unified memory architecture, GPU cores have direct access to all RAM, effectively turning it into a shared CPU/GPU resource. In my tests, for smaller models (under 24 GB) it matches CUDA performance. At the moment, memory of Apple Silicon is capped at 192 GB, however Apple already confirmed the next generation is going to be available in 256 GB / 512 GB configurations. Those are poised to become the most affordable devices to be able to fit LLAMA’s 405b variant in GPU directly-accessible memory.
Based on the most optimal configuration I tested (GPU+DDR5), we can calculate a potential Return on Investment vs the cloud offering of OpenAI. Assuming the build is around $3,500, that yields an average number of 44,000 items to break even. If your workflow involves scanning emails or any large volume processing, that number can be reached within weeks. At full utilization and assuming 30 seconds per item, the minimum time is 15 days.
But costs are not the only reason to consider LLAMA.
Why Bother?
While GAN models have been popularized as self-hosted tools, the same cannot be said about LLMs. There have been attempts by Google (with gemma and gemma2) and others to conquer the space, but they all fail short when it comes to performance against their cloud counterparts. My runs with LLAMA reveal part of the reason – it’s the sheer model size that makes it unsuitable for running on commodity hardware, especially when real-time responses are demanded.
And then along comes Meta and releases 3.1:405b. This changes things dramatically. It allows for AI applications which were not previously possible, due to reasons such as:
Compliance – With LLAMA running entirely on-premise and offline (it can be fully air gapped from the Internet), companies can now use it to automate their pipelines involving sensitive information (PII, PCI, and so on). Previously, even if secret data was not directly a subject of AI processing, the mere fact of having to share sensitive documents with 3rd parties (such as OpenAI) would prevent many from being able to use them in their field.
Privacy – In a similar manner, researchers and activist can now interact with this powerful LLM without fearing the consequences of their activity being censored, monitored and penalized. You can spin up a temporary environment, send your prompts and then wipe it clean leaving no trace of your AI activity.
Business Permanence – It is all too common for companies and individuals to build dependency on a third party tool, only for the provider company to take it away from them (see Google Graveyard). Becoming vendor locked by OpenAI isn’t that much different from committing to a bespoke cloud database offered by AWS or Azure. It is great when it works, but you have zero control over its availability (and pricing). In case of LLAMAs, cat is out of the bag for good. Nobody can take it away or lock your access to it.
Ideological Permanence – IT products are not immune to political and cultural changes. Oftentimes, changes are forced upon existing applications to make them more in line with current views and trends. Examples would be Microsoft GANs being taken down because of politically incorrect use, YouTube removing downvotes, etc. While the validity of those changes is a subjective matter, they are very disruptive to automation. For instance: you can imagine how tweaking LLMs to appease certain groups affects your existing prompts which you spent massive resources tweaking to perfection. While LLAMAs are surely not free from ideological influence, it is all contained in the training phase. Once the models are out – they are just regular files. You have full control over when and if they need to update.
In today’s world where work (and play) tools are becoming centralized and leased rather than owned (subscriptions, cloud hosting, game and video streaming, and so on), we are gradually deprived of any control over our digital assets. It is very refreshing to see something going against this trend. It is even more surprising if we remember that it’s Meta (Facebook) who provided us with this alternative.
Consequences for OpenAI
Why was LLAMA released in the first place? In his Open Letter, Mark Zuckerberg gives a few technical reasons (Meta being involved in open source, competitive development, and so on), ultimately recognizing that monetizing LLM access isn’t Facebook’s bottom line. While a true statement, it surely doesn’t apply to companies such as OpenAI, who have already poured tens of billions of dollars into training their models.
With openly accessible alternatives release, are their future profits in danger? I would answer with a resounding yes. They won’t be going anyway anytime soon, but their LLM monopoly is surely coming to a very abrupt end.
Self-hosted models provide unique benefits that outweigh anything a cloud provider can offer. Even if access to GPT was given away for free, my four arguments listed above would still stay. For me personally, working in a tightly regulated financial industry, LLAMA allows for opportunities that would simply never exist with a cloud AI. No matter how good, robust or cheap it was. I can only imagine there are other fields (such as legal, medicine, intelligence, etc.) in a similar position.
For non-realtime workflows, the ROI is very quick and initial cap-ex remains low. Enterprises will also save money on the model’s (and its hosting) permanence, not having to update their API workflows any time an AI provider changes something on a whim.
On the day I am publishing this post, OpenAI’s co-founder announced his departure for a rival company. Between the proliferation of unified memory hardware spearheaded by Apple and this surprising emergence of self-hosted LLMs, the future for AI might – after all – be open.