With the dawn of new era dominated by web scale technologies, financial services might be one of the few markets, where data consistency and operational reliability outweighs (often questionable) performance advantages of noSQL.
Webscale With Care
Having said that, rapid responses were listed in my original article as one of the three key requirements for our setup. We had to design a solution that is capable of keeping the fast pace under heavy load without compromises in the fields of coherence and reliability.
One could say – all it takes is to build a separate dedicated data storage with pre-processed statistical information and discard everything else. This approach would most definitely work for the most common demographic reports and we do in fact use fact tables for our OLAP cubes. However, certain inquiries rely on live data to deliver a meaningful response. These types of queries have to be run against production database.
For instance – an anti-fraud module used by our credit card authorization facility needs to have full unabridged access to operations on an account to protect consumers against accidental double charges. Searching for a matching recent transaction in a pre-buffered dataset certainly does not make too much sense and would seriously compromise this feature.
That’s not to say that scalability doesn’t matter. Fin ops systems are by definition highly available and have to be ready to cope with increasing demand as well as irregular load patterns, like holiday seasons – take Black Friday for instance. Unfortunately, a financial institution cannot make performance its #1 priority, as this spot is already occupied by security, which does imply data consistency. For this reason, relational databases are not going anywhere – not today, not in this decade. Other industries suffer from similar dilemmas – take space exploration, which despite pushing the frontier of humanity, still uses CPUs from previous century.
Reality Check
Rather than replacing SQL databases by new hip products with catchy names, our job is to make them perform in this unnatural cloudy environment and deliver features like HA and scalability without compromising the safety of customers records. Luckily, there is a growing community of developers sharing similar principals, who provide the industry with some amazing tools to do so.
PostgreSQL has been around for 20 years and has established its position as a leading open source ACID compliant relational data storage. With its value recognized by many successful commercial projects, it has been a database of choice for most of my fintech projects. It provides rock solid foundation required for storing financial records. And thanks to its open source nature, it’s highly adaptive and can be adjusted to purpose-built to perform in the most demanding of circumstances.
The setup we are going to describe in these series is based on a real-life installation currently providing various analytical data for a retail banking software offering revolving lines of credits available online with access to funds through a credit card.
Setup Criteria
Our environment has the following characteristics:
- All credit products are based on progressive APR or progressive EAR.
- 24/7 access to credit lines via online banking and credit cards.
- Circa 1 million active accounts, 95% of transactions during US business hours.
- New application evaluation through online lead interface.
- Active marketing campaigns expanding customer base to new states.
- Multiple customer service centers in various geographical locations.
There are two main types of queries our risk mitigation system has to deal with:
- Statistical – for lead verification, progressive APR/EAR, marketing support.
- Operational – for transactions approval & oversight.
Let’s put together a list of requirements that our database has to keep up with in order to support the features outlined above.
High Availability
Due to critical nature of risk mitigation procedures, they are mandatory in order to authorize any transactions on customer accounts, including card payments. Should this system become unavailable or overwhelmed by high volume of operations, all pending transactions will be declined (or in certain cases might take longer than usual to complete). Auxiliary services, like lead interfaces, would be completely disabled in order to provide high priority access to database resources for the core modules.
Even though full hardware redundancy can be achieved these days quite easily, the same cannot be said for Internet connectivity, which by its nature is dynamic and volatile. To maximize availability, cross-datacenter replication is required.
Master-Master
While it is fairly common in the US (but still surprising for a European) to have certain online banking features disabled outside business hours (like international wires, ACH transactions, etc.), our credit lines need to be available 24/7. Even though extensive maintenance windows would be acceptable for web-based services, the same cannot be said for credit card authorizations.
Apart from end-user functionality, our system supports branches dedicated to customer acquisition, which operate from remote locations. It would be highly disruptive if their work had to be put on hold every time there are connection issues between our nodes (or a write-enabled node becomes unavailable).
For these reasons, the only solution that guarantees maximum performance and the best customer experience is a master-master replication, with each location being able to read and write into the database. Unfortunately, relational databases have not been created with this design in mind and it will come with certain strings attached. I will describe them in greater details in a separate note dedicated to implementation constrains.
High Performance
It comes as no surprise that performance would be the key factor as far as user experience is concerned. There are certain usage patterns where it becomes even more critical. For instance – a commerce involved in ping-tree based lead exchange has a limited time to asses and evaluate incoming offers.
As we will show in details later on, there are usually two data source types associated with risk analysis queries. First – there is live ops, which by its nature needs to execute queries against an unabridged live copy of a database and then there are OLAP cubes, which work with pre-assembled fact tables.
Both types typically share one attribute: the majority of queries will be based on extensive JOINs. This fact will play an important role in keeping the execution times low to a minimum.
The Big Trio
Combined, these 3 requirements form a pretty demanding structure that our database will have to cope with. The good news is, there is no need to reinvent the wheel: there are PostgreSQL-based solutions available that will meet all of our needs while leaving enough room for future expansion.
HA is the easiest of them all, as it’s available with Postgres out of the box. As our queries are read-only, WAL-based replication is all we need to provide a scalable and dedicated cluster while isolating server load from our core systems.
Master-Master is a tad bit trickier. We’re basically asking a relational database to perform in a way it was never designed to. For this job, we’re going to rely on another product from a very experienced and established developer: BDR. With global sequence generators and conflict logging, it can ensure data remains coherent even with x-dc replication.
There’s no other type of software hungrier for performance than games. Computer entertainment is the driving force behind new generations of GPUs hitting store shelves on a regular basis. Thanks to open architecture of computing APIs provided by their manufacturers (like CUDA), we can tame all that power and put it to good use with PGStorm – a Postgres extension that offloads CPU based tasks to GPU. It is advertised to work particularly well with join-heavy queries and oh boy, does it deliver on these promises.
The Big Picture
With all pieces put together, our database structure looks somewhat like this:
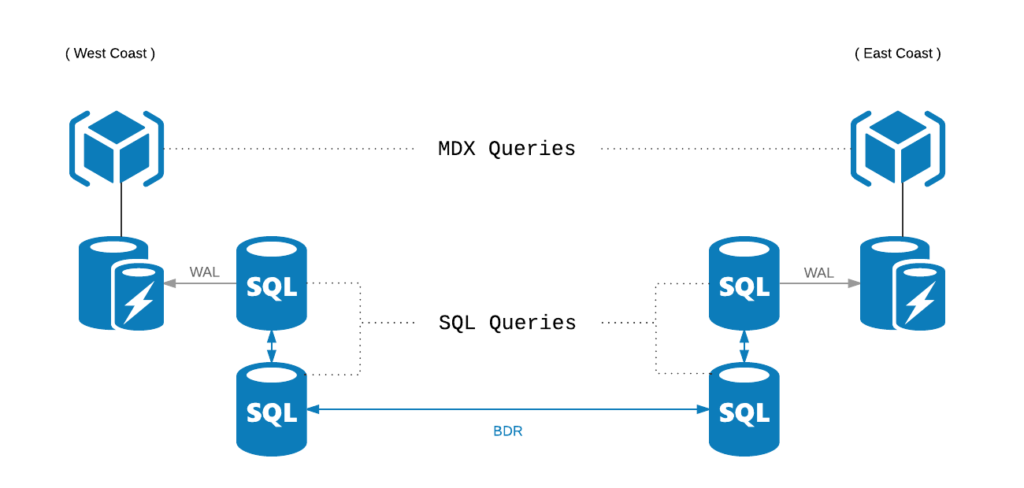
BDR acts as a main data link between our locations. And with BDR nodes being the only ones supporting writes, our primary goal is to shift all other (i.e. read only / volatile) usage patterns to separate servers.
Within each location, BDR node is a Master for an old-school WAL based replication, which feeds live ops data to an array of read-only, GPU-enhanced stations. Additionally, pgbouncer is used as dispatcher which makes sure that only write/blocking queries bother the BDR.
Volatile data (sessions, call center queues, etc.) is handled by auxiliary Redis storage and kept up to date with an army of celery workers. This keeps its SQL footprint minimal and makes the whole system scalable by design.
2 thoughts on “Risk Mitigation Network 1/4 – Database Structure”